
In today's world, in any industry, customers have multiple options to choose from like in Telecom, we have AT&T, Verizon, T- mobile, etc, in Media, we have Netflix, Amazon Prime, Apple TV, etc. and similarly for others.
In this highly competitive market, the industries face a large number of customer churn. Considering that obtaining a new customer costs 5-10 times more than maintaining a current one, hence, retention of customers has now become even more important than acquiring a customer.
Here we are going to take data from one of the telecom company, to understand the customer churn.
What is the customer churn?
If a client or subscriber ceases to do business with a company or service, its called Customer Churn.
Now let's take a deep dive to understand why the Customer Churn happens and how to predict it before happening.
So let's start coding.
Now let's take a deep dive to understand why the Customer Churn happens and how to predict it before happening.
Understanding the data
Before working on any model, we need to understand the data and try to analyze it, to prepare for our approach.So let's start coding.
Importing libraries
Data Processing
Data
Let's look at the data and try to see understand the columns.
Below is the sample data from your reference.

Below is the data dictionary to understand the column names-

The above data shows us the pattern of user expenditures for 4 months.
Understanding Customer - The Good, The Bad and The Churn
Now, let's understand how can we identify the customers who are going to churn.
In churn prediction, we consider three phases of a customer-
In churn prediction, we consider three phases of a customer-
The Good
In this phase, the user behaves normally and is happy with the services.The Bad ( Action Phase )
In this phase, the user behavior starts changing. This may be due to good offers from competitors, any services issue, user is unhappy, etc. This is the most critical phase because if we can identify the user in this phase we prevent the churn.The Churn
In this phase, the customer has moved out i.e. churned.
Now let's see how can we calculate the churn score to identify the churn customers.
Now let's see how can we calculate the churn score to identify the churn customers.
Identifying High-End Customers
Ideally, we should be interested in high-end customers only, because they are the ones which provide major revenue.
In this case, we can take the top 70% of the customer based on the recharge amount in the first two months( the good phase).
Labeling the Churn Customers
Label the customer as churn =1 those who made no calls (whether incoming or outgoing) AND did not use mobile internet even once during the Churn phase.
Now let's see the data after tagging.
Since we have only around 9% churn ratio, the data is imbalanced. We will see in later sections, how to fix this imbalance issue.
Deriving Columns
In the cases where we have quite a large number of columns, its always advisable to derive/merge the columns and then drop the ones which are duplicate or no longer required.
E.g.
Data Imbalance
Data imbalance is one of the major issues when we have very little data for one of the class than another. This causes the impact of the minor class to be minimal for any of the metrics. This can be solved by many of the options. You can read more about data imbalance here.
Here we are going to use SMOTE:

SMOTE aims to balance class distribution by randomly increasing minority class examples by replicating them.

Model Building
For the model building, we will be splitting the data into the 70-30 ratio for train and test. We should never test the model on the data in which it is trained.
Now we will be looking into different options using which we can identify the churn.
PCA (Principal Component Analysis)
Viewing the first few PCA components corresponding to columns.

We can also view the PCA components through scatterplot as below.

We can also plot the cumulative variance against the number of components

Now let's use theses PCA components for our model.
Model Selection
Now let's see different techniques for the model.
Logistic Regression
Logistic regression is a statistical model that in its basic form uses a logistic function to model a binary dependent variable.
Performance Metrics
We can check the performance of the model through the confusion matrix.
Viewing 2 Components

Viewing 3 Components
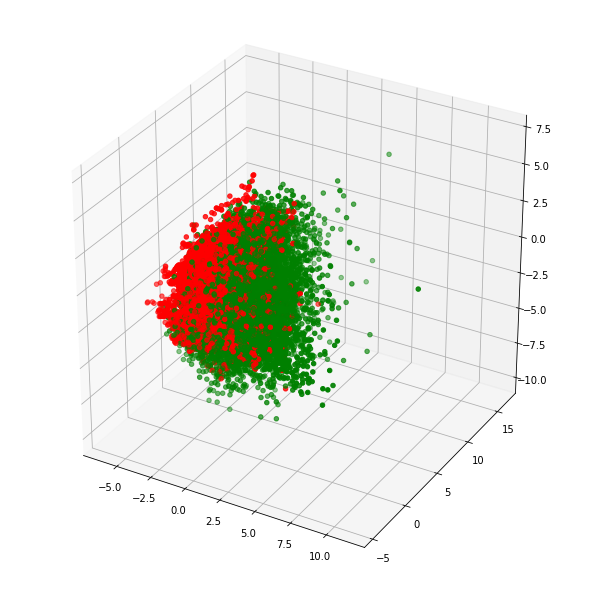
We can see the pca variance ratio for each of the components as below.
Decision Trees
It looks like a tree upside-down. It's also very close to how you make real-life decisions: you're asking a number of questions to make a decision.
A decision tree splits the data into several sets. Then each of these sets is further divided into sub-sets in order to reach a decision.
Importing libraries
Tuning Hyperparameters
Gini Score
Confusion Matrix
Viewing the Decision Tree
A Sample from the decision tree.

Decision Trees also helps in identifying the important columns. We can get the important columns as below.

Random Forest
A random forest is almost always better than a single decision tree. This is the reason why it is one of the most popular machine learning algorithms.
As its name implies, random forest consists of a large number of individual decision trees that act as an ensemble. Every individual tree spreads a class prediction in the random forest and the class with the most votes becomes the prediction of our model.
Tuning Parameters
Optimal accuracy score and hyperparameters
Fitting model with the optimal parameters
Confusion Matrix
Decisions on Model Selection
Now, if we compare the performance of all the above models. We can say that here the logistic regression or Decision Tree as it has higher accuracy than Random Forest.
Conclusion
Based on the above analysis and models we have below attributes that contribute towards Customer Churn.
- arpu_8 - Average revenue per user in the action period - In the action period when the average revenue from the user is varying down, it provides a strong indication that the user is about to churn
- days_since_last_recharge_8 - No. of days since the user has done recharge in action period - Keep track of the last recharge day in the Action period. If they are not recharging after a threshold time, the company should try to provide more exciting offers' information as a message or special offers/gifts for those users.
- last_day_rch_amt_8 - Amount of recharge done on the last day in action period- Check the amount of the recharge done by user, if the user has done recharge, he is likely to continue. Else if the user is doing small recharge, they may churn as they no longer want to use the service. The company should try to provide more exciting offers to these users.
- sachet_2g_8 - Service schemes with validity smaller than a month for 2g in Action Period- Keep track of 2g sachets bought by the user. If the user starts buying a lesser amount of sachets, he is likely to churn.
- std_ic_t2t_mou_hp - Minutes of Incoming STD calls within the network in Happy Period- User who has low incoming STD calls within the same network, is likely to churn. The user might have taken another mobile no. hence this no. may not be his primary contact now.
- vol_3g_mb_8 - Volume of 3g recharge done in Action Period- Check the volume of recharge done for 3g, if the user is not recharging in the amount they used to, the company should try to attract them with offers.
- total_rech_num_hp - No. of recharge done in the happy period- If the frequency of recharge reduced for the user in the happy period, he is likely to churn.
- total_ic_mou_hp - Minutes of Incoming calls in Happy Period- User who has low incoming call in happy period, is likely to churn. The user might have taken another mobile no. hence this no. may not be his primary contact now.
- aug_vbc_3g - Volume-based cost - when no specific scheme is not purchased and paid as per usage in Action Period- If the vbc for the user decreases, the user is likely to churn.
- max_rech_amt_8 - Max amount of recharge done in Action Period- If the user's max recharging amount starts reducing, the user is likely to churn.
- days_since_last_recharge_hp - No. of days since the user has done recharge in Happy period- Keep track of the last recharge day in the Happy period. If they are not recharging after a threshold time, the company should try to provide more exciting offers' information as a message or special offers/gifts for those users.

Thanks for sharing your thoughts. I truly appreciate your efforts and I will be waiting for your further write ups thank you once again.
ReplyDeletechurn prevention software